「表二謬誤」
在有向無環圖(DAG):Y ← C → X → M → Y 中,C 稱為「干擾變項」,M 稱為「中介」。
校正 C 之後 X 與 Y 的相關稱為「總效應」(等於直接效應(DE)+ 間接效應)。把 M 操弄在一個特定 m 的 DE 稱為「控制直接效應(CDE)」,不操弄 M 的 DE 稱為「自然直接效應(NDE)」。
大部分研究因果關係的論文的表ㄧ都是基本資料的描述性統計,表二則是廻歸統計的結果,亦即用許多干擾變項 C 來校正暴露變項 X 與結局 Y 的關係。
有向無環圖(DAG)與因果關係
假設 X 是原因, Y 是結局:
有向無環圖(DAG)的分類是樹狀(X ← C → Y):C 稱為「干擾變項」(X 與 Y 的共同原因)。用 C 等於一個特定的 c 制約之後,X 與 Y 之間的「虛假相關」就會消失,校正 C 之後 X 與 Y 的相關稱為「總效應」(等於直接效應(DE)+ 間接效應)。C 是 X 與 Y 之間路徑的後門,當後門被關起來(制約)之後,如果 X 與 Y 之間仍然有相關,那麼我們就能知道 P(Y|do(X)),do 是「介入」,亦即X 與 Y 之間有因果關係,此方法稱為「後門校正」。偏偏大部分的 C…
因果關係的推論
用演繹法做因果關係的推論,只要前提正確,而且遵從邏輯學的規律,那麼結論一定是對的。
例如:若是細菌感染,則要用抗生素治療,因此用抗生素治療之前一定要先做細菌培養;所有的藥物都有副作用,因此沒有副作用的一定不是藥物。
但是歸納法的結論並不一定對,因為可以用「反證法」來推翻。例如:在歐洲的天鵝都是白色的,因此人們認為所有的天鵝都是白色的。但是自從在澳洲發現黑天鵝以後,這個「白天鵝」理論就被推翻了。
相反流行病學
中國人是世界上最早使用負數的民族,西方人卻ㄧ直到16至17世紀時才勉強接受了負數的觀念,因為歐洲務實的牧羊人在數羊的時侯是不會數到「負ㄧ頭羊」的。
宇宙中有物質也有反物質,例如正子發射斷層攝影(PET)中的正子是電子的反物質(發現者是1936年諾貝爾物理學獎得主卡爾·安德森,Carl Anderson),當正子與電子碰撞時就會互相煙滅。
許多人在聽到哥倫布向西班牙國王提出向西航行到東方的大膽構想時,都嘲笑他以為他瘋了; 人類剛發現地球是圓的時侯,許多人也吃驚的發現地球另ㄧ面的人是倒立著生活的,卻不會掉落到外太空去。
不確定的世界
人類天生喜歡確定的東西,卻討厭不確定的東西。
從17世紀開始有了長足進步的科學似乎也證明了世間萬事萬物都是確定的:牛頓在 1687 年發現了萬有引力及物體的運動定律,拉普拉斯甚至在 1814 年提出了「拉普拉斯妖」假説,他説如果有一個精靈知道宇宙間從古到今所有的知識,那麼那位精靈就能預知從此以後宇宙間所有的事情,這就是「科學的確定論」:凡事有因必有果。
但是愛因斯坦在 1916…
科學與偏見
費雪(Ronald Fisher)是一個偉大的統計學家與遺傳學家,他發明了變異數分析與定量遺傳統計學。
誤差有兩種
胡適的「差不多先生」提醒中國人要在乎正確性和精確性,因為正確性和精確性似乎是當時西方哲學和科學的基礎。
十九世紀時的數學和科學有了突飛猛進的發展,例如牛頓的萬有引力數學公式可以精確的預估所有物體(包括天體)的運動和位置,甚至當時的人們樂觀的認為有一天測量的誤差將會消失。
但是當測量的儀器愈來愈精準時,人們卻發現誤差仍然頑固的不肯消失,這是因為所有的統計估計都會有誤差(一般用平均平方誤差來表示):誤差等於隨機誤差加系統性誤差。
正確性與變異性
中國人認為中庸(中道)是美德,西方人也認為做人要公正,例如西方的法院前面都有一個蒙著眼睛的正義女神手中拿著一個天平,可見不偏不倚(正確性)是評斷所有事物的普世標準。
研究時我們會對一個資料建立模型,其目的是正確説明現有的資料或預測新的資料,其中預測的正確性是該模型是否能被廣泛運用的一個重要條件。
或許有人認為正確性(效度)是唯一的條件,但是一個正確但不精確的預測是不可靠(沒有信度)的,亦即具有低的再現性:例如有一家公司製造了一千個鐘,其平均時間與標準一樣,但是其 95%…
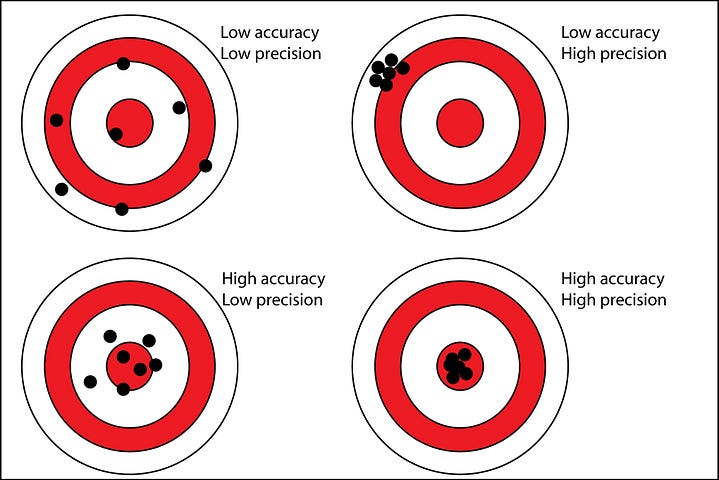
正確度與精確度
我們用正確度(accuracy)與精確度(precision)來評估測量的用處。
正確度又稱為效度(validity),亦即測量值與真值(金標準,例如腎絲球過濾率的金標準是菊糖廓清率)間符合的程度,測量值與真值間的差距稱為誤差,誤差有兩種…
「忘記歷史的人」
「頻率學家」對傳統機率(P)的定義是長期下來觀察到某事件發生的頻率,勝算等於 P/(1-P),逆機率則是某未知模式或參數的機率。
大部分的機率是條件機率,例如: 當我們看見(實驗或觀察的)資料(本班大ㄧ男生的平均身高)時,在某模式(M,例如: 常態分布)下某資料(D)發生的頻率 P(D|M) 就是似然率。假設只有兩個模式 M1 與 M2,那麼 M1 的似然比等於 P(D|M1)/P(D|M2)。推論統計是用模式中的參數作出函數,藉以預測資料,其中 P 值的定義是如果「虛無假設」M 正確時比某資料更極端的資料發生的機率 P(D|M)。