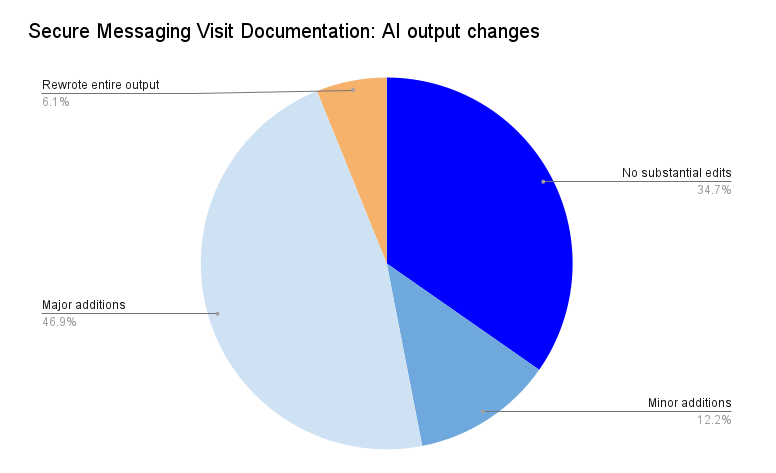
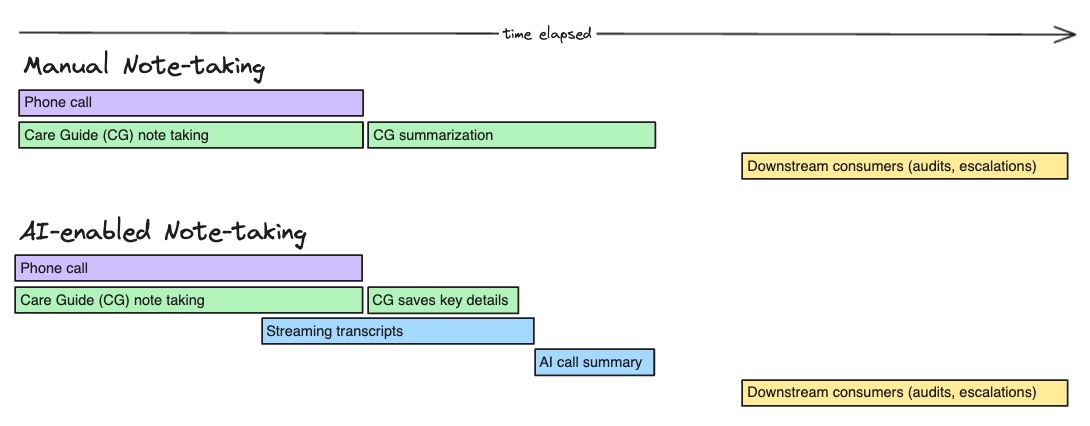
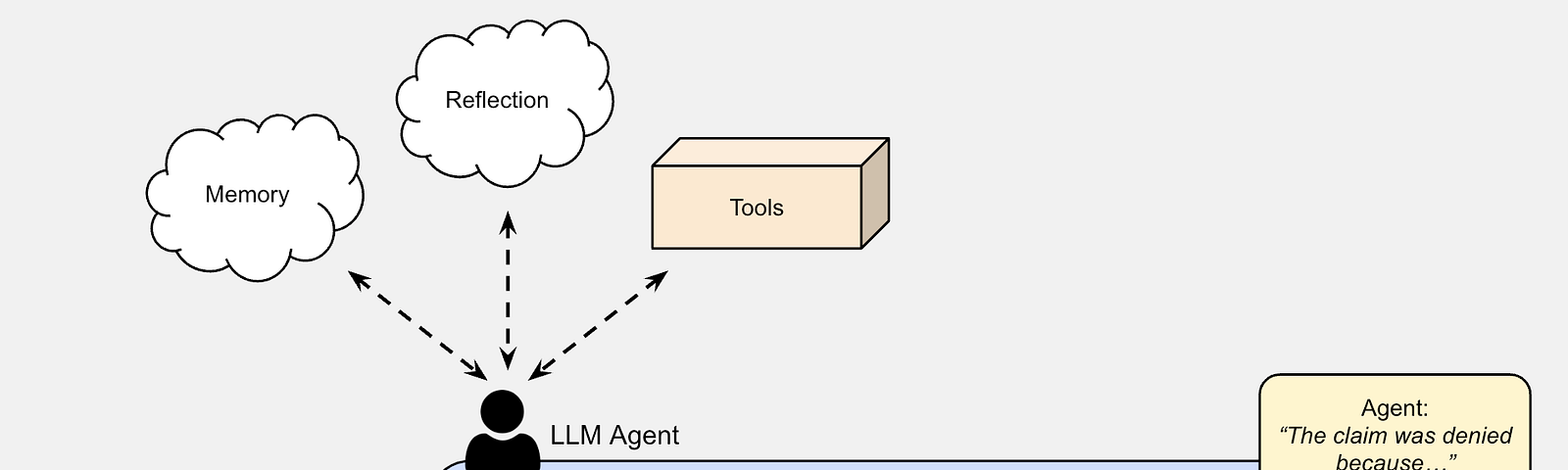
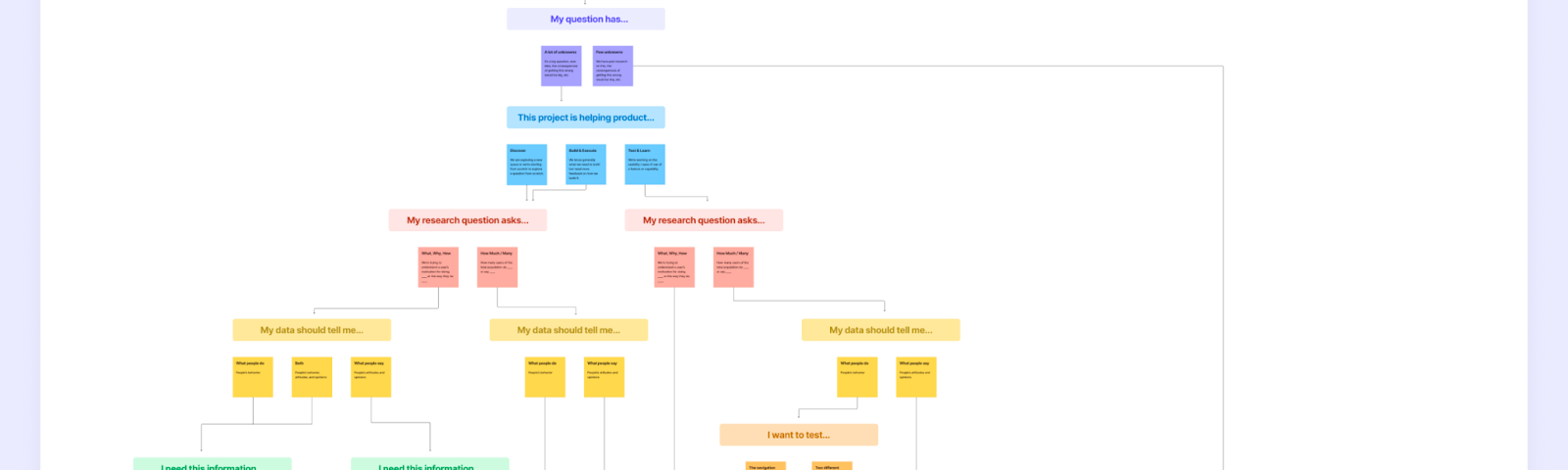
by: Celina Leong, Dan Ariniello, and Yvonne Wang
By Madi Shultz
By Tory Grimley and Caleb Bank
By Lei Zhao
By Dar Min & Sydney Choi
By Lauren Pendo
Benchmarking model performance at Oscar
The pace of improvement of large language models (LLMs) has been relentless over the past year and a half, with new features and…