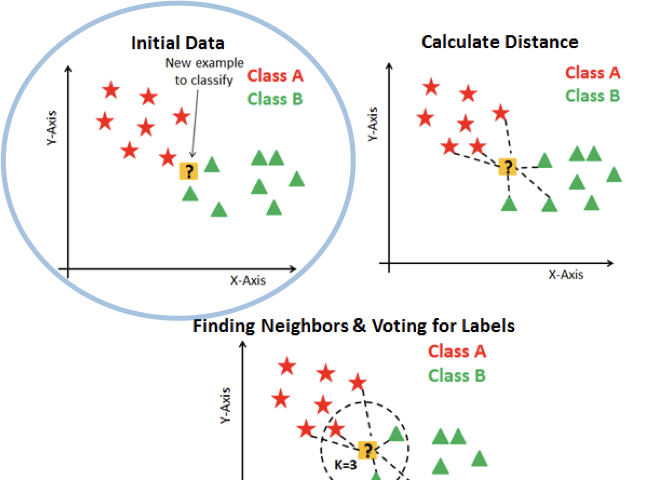
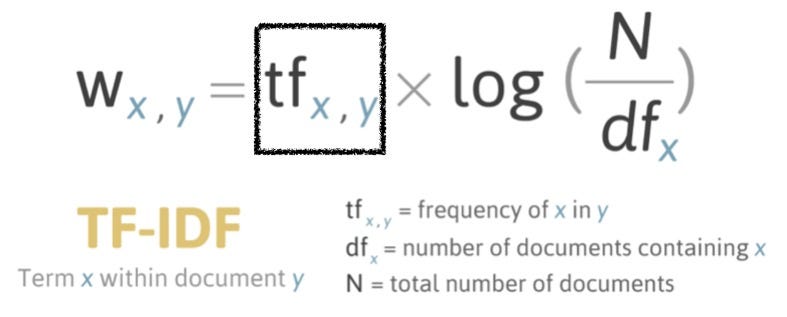K-nearest neighbors 演算法(KNN)是監督式學習中的分類演算法(classification)。簡單來說,要預測資料的類別是取決於K個最相近訓練資料的類別,以下會有更詳細的說明。
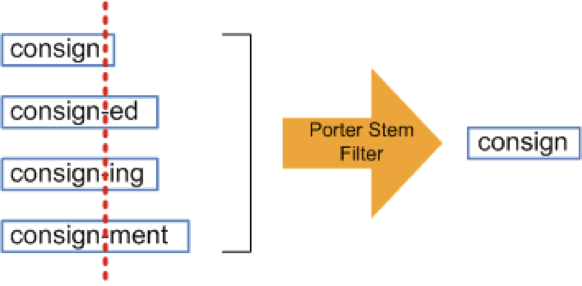
在英文語句中,同一個單詞的拼法可能會隨著時態、單複數、主被動等狀況而有所改變,如 speaking / speak 或是 cats /…
Naive Bayes 會用到條件機率的觀念,所以我們先從條件機率開始,再討論Naive Bayes
條件機率
條件機率寫為P(A|B),就是在 B 事件發生的前提下,A 事件發生的機率。
也可以轉換成
P(A∩B)稱為聯合機率,就是在A,B同時發生的機率。如果A,B兩個事件是獨立的事件,也就是符合特徵獨立假設,那P(A∩B) = P(A)*P(B)
在進行字詞向量化之前,我們需要針對文本資料進行前置處理,針對文本資料處理的方法很多,而本文會討論的包含「字詞移除標點符號」、「字詞轉換成字詞 ID 清單」、「文本轉化為數字的 ID 形式表示」
一般我們看到的資料會像是左側這張圖用label encoding,從這張圖的1,2,3人類可以很輕鬆地知道是指三類物品,但電腦中1,2,3是有大小關係的,如果維持這樣的呈現,數字大小的意義會影響演算法,因此我們要換成one-hot encoding的方式呈現,才沒有強弱之分,例如蘋果就是[1,0,0]對應95的卡路里,雞肉則是[0,1,0]對應231的卡路里,以此類推,種類越多,one hot encoding的長度就越長。
word embedding的主要類型
詞嵌入根據方法的不同主要可以分為以下三類:
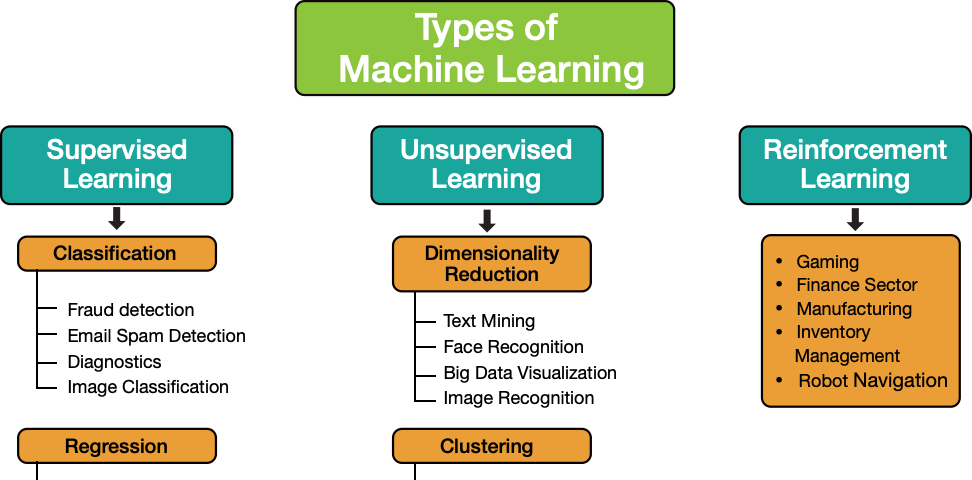
機器學習種類可以分為監督式學習、非監督式學習及強化學習
監督式學習需要標注檔案(Labeling),主要可以分為分類問題(classification)與回歸問題(regression)。