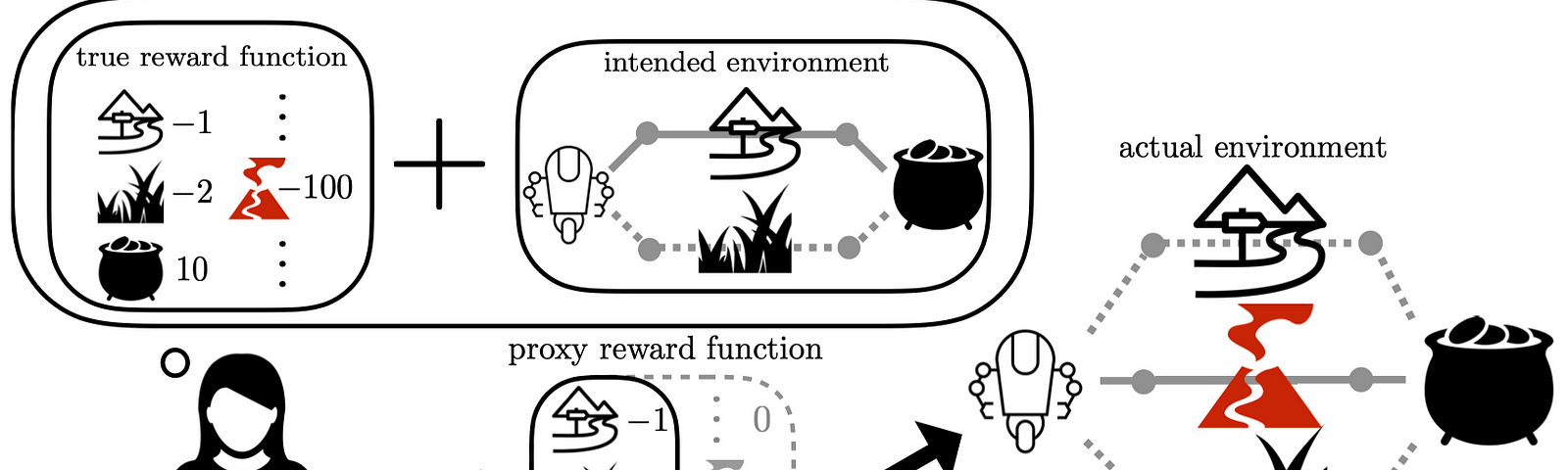
在强化学习的MDP模型中,对于Reward函数的设计一直是智能体能否完成目标任务的核心关键,同时也是一个非常复杂的课题。目前非常多的强化学习算法都应用在规则明确的游戏领域,正是因为在这些场…
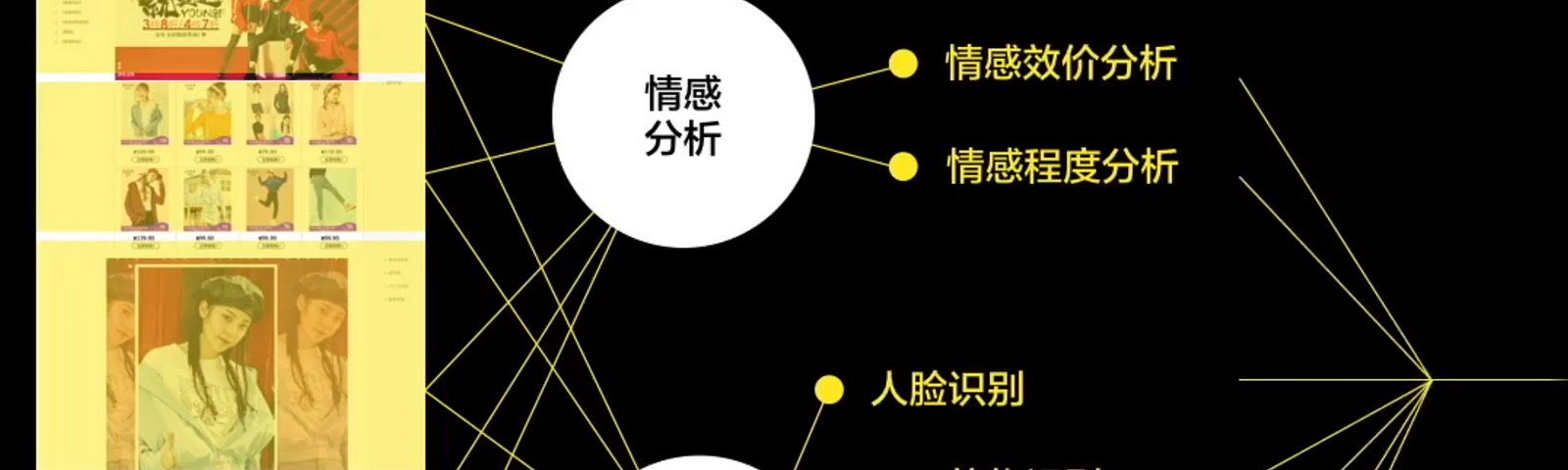
本文是Alibaba Wood的技术视频截图,官方地址: Alibaba Wood
(1) 商品页分析